
با انتشار NET 10. مایکروسافت گام بزرگی در بهبود عملکرد و کارایی برنامهها برداشته است. این نسخه، از مدیریت حافظه هوشمند و JIT پیشرفته گرفته تا بهینهسازی محاسبات عددی و threading، امکانات جدید و جذابی برای توسعهدهندگان ارائه میدهد. اما سوال مهم این است: این بهبودها چقدر واقعی هستند و در مقایسه با رقبای محبوب مثل Node.js و Go چه عملکردی دارند؟
در این پست، ۲۲ مورد از کلیدیترین بهبودهای NET 10. را بررسی کرده و عملکرد آنها را با Node.js و Go مقایسه میکنیم. با این بررسی، توسعهدهندگان میتوانند تصمیم بهتری برای انتخاب پلتفرم مناسب پروژههای خود بگیرند.
با بهینهسازیهای جدید در تولید کد، باعث اجرای سریعتر برنامهها میشود. این بهینهسازی شامل تولید دستورالعملهای کارآمدتر و کاهش سربار پردازشی در زمان اجرا است.

JITیا Just-In-Time Compiler یک روش اجرای برنامه است که در آن کد سطح بالا (مثل C#, JavaScript یا IL در .NET) در زمان اجرا (runtime) به کد ماشین تبدیل میشود.
این روش برخلاف AOT (Ahead-of-Time) که همهچیز را قبل از اجرا کامپایل میکند، انعطاف بیشتری دارد چون میتواند:
نتیجه: JIT معمولاً شروع کندتری دارد، اما کارایی بالاتری در طول اجرای طولانی به دست میآورد.
در Net10. در اجرای طولانی و اپلیکیشنهای سازمانی یا محاسباتی بسیار سریع عمل میکنه، و با ترکیب JIT + Native AOT بهترین تعادل بین startup و throughput رو فراهم میکنه
در node.js برای کدهای JavaScript سبک و متوسط خیلی سریع عمل میکنه، ولی در workloadهای محاسباتی سنگین (مثل ML یا پردازش تصویر) نسبت به .NET یا Go ضعیفتره چون JavaScript ذاتاً dynamic type هست
زبان Go بهطور پیشفرض JIT نداره.
Go از AOT Compilation استفاده میکنه: کد Go همیشه قبل از اجرا به باینری native کامپایل میشه.
این یعنی:
Startup فوقالعاده سریع 🚀
باینری مستقل بدون وابستگی به runtime حجیم
ولی: بهینهسازیها به اندازه JIT پویا و تطبیقی نیست (نمیتونه در زمان اجرا خودش رو optimize کنه)
برای سرویسهای کوچک و مقیاسپذیر (microservices, cloud apps) عالیه چون سرعت شروع بالایی داره و memory footprint کمی مصرف میکنه، ولی برای workloadهای سنگین که adaptive optimization نیاز دارن، ضعیفتر از .NET و Node.js هست
| ویژگی | NET 10. | Node.js (V8) | Go (AOT) |
|---|---|---|---|
| نوع اجرا | JIT + AOT ترکیبی | JIT (Ignition + TurboFan) | فقط AOT |
| Startup | متوسط (Tier0 سریعتر شده) | سریع | بسیار سریع |
| Throughput (اجرای طولانی) | بسیار عالی (PGO + SIMD + AVX) | خوب ولی محدود به JS | خوب (ثابت، بدون adaptive) |
| بهینهسازی پویا | دارد (Profile-Guided + Tiered) | دارد (Speculative) | ندارد |
| پردازش سنگین (HPC, ML, AI) | عالی 🚀 | ضعیف ❌ | متوسط |
PGO (Profile-Guided Optimization) -2
PGO پویا با جمعآوری اطلاعات در حین اجرای واقعی برنامه، مسیرهای پرکاربرد و الگوهای ورودی رایج را شناسایی کرده و کد را بر اساس آن بهینه میکند. این موضوع باعث کاهش تبدیلهای غیرضروری (casts) و افزایش کارایی میشود.

Profile-Guided Optimization (PGO) یک تکنیک بهینهسازی است که در آن اطلاعات واقعی اجرای برنامه (مثل مسیرهای پرتکرار، نوع دادهها، شاخههای if/else که بیشتر اتفاق میافتند) جمعآوری میشود و سپس کامپایلر یا JIT بر اساس این دادهها کد را بهینه میکند.
به جای حدس زدن، کامپایلر میداند کدام بخشها بیشتر استفاده میشوند.
مسیرهای مهمتر سریعتر اجرا میشوند (hot paths).
کدهایی که کمتر استفاده میشوند، سادهتر باقی میمانند (cold paths).
در NET 10، PGO. به صورت Dynamic PGO و Static PGO پشتیبانی میشود:
Static PGO → پروفایل قبلاً جمع میشود (مثلاً در محیط تست) و هنگام build استفاده میشود.
Dynamic PGO → خود JIT در زمان اجرا پروفایل میگیرد و بهینهسازی میکند.
نتیجه: کدهای پرتکرار در NET 10. بسیار سریعتر از قبل اجرا میشوند.
موتور V8 چیزی مشابه PGO دارد به نام Speculative Optimization.
V8 فرض میکند که انواع داده یا مسیر اجرای کد ثابت باقی میماند (مثلاً یک متغیر همیشه عدد صحیح است).
بر اساس این فرض کد را optimize میکند.
اگر فرض اشتباه شود → Deoptimization اتفاق میافتد (یعنی برمیگردد به حالت سادهتر و کندتر).
Node.jsدر workloadهای عادی وب خیلی سریع است، اما اگر دادهها به شدت تغییر کنند، overhead از دست دادن optimizeها زیاد میشود.
زبان Go به صورت پیشفرض PGO ندارد چون JIT ندارد.
ولی از Go 1.20 به بعد، یک نسخه Profile-Guided Optimization ساده معرفی شد:
هنگام build میتوان پروفایل جمعآوری شده از اجرای قبلی را به کامپایلر داد.
این باعث میشود مسیرهای پرتکرار (hot path) کمی سریعتر شوند.
اما: این PGO هنوز به بلوغ .NET یا V8 نرسیده است.
Go بیشتر روی سادگی و سرعت ثابت تمرکز دارد تا adaptive optimization.
| ویژگی | NET 10. | Node.js (V8) | Go |
|---|---|---|---|
| نوع | Static + Dynamic PGO | Speculative Optimization | Static PGO ساده (Go 1.20+) |
| زمان اجرا | Adaptive (خود JIT پروفایل میگیرد) | Adaptive (ولی ممکن است deopt شود) | فقط هنگام build |
| بهینهسازی نوع دادهها | عالی (casts, generics, branching) | خوب (speculation) | محدود |
| ریسک rollback | ندارد (adaptive پایدار) | دارد (deoptimization) | ندارد |
Tier 0 Optimizations -3
بهبودهای Tier 0 باعث کاهش زمان راهاندازی (startup) برنامهها میشود. این کار از طریق حذف boxing غیرضروری و بهینهسازی عملیات async/await انجام شده است.

در پلتفرمهایی که JIT دارند، همیشه یک چالش وجود دارد:
اما JIT نمیتواند همزمان هم خیلی سریع کامپایل کند و هم خیلی بهینه.
اینجاست که مفهوم Tiered Compilation میآید:
نتیجه:
Startup خیلی سریعتر
Hot paths خیلی بهینهتر
ترکیب مناسب برای اپلیکیشنهای طولانیمدت (server-side apps)
V8 چیزی مشابه Tiered Compilation دارد:
Ignition → یک مفسر (interpreter) سریع برای شروع کار
TurboFan → JIT optimizer که بعد از مشاهدهی کد پرتکرار، نسخه سریعتر تولید میکند
این همان ایده Tiered Compilation است اما با اسم متفاوت.
تفاوت:
زبان Go JIT ندارد، پس چیزی مثل Tiered Compilation هم ندارد.
همیشه کد از قبل کامپایل شده (AOT) و بهینه است.
یعنی Go در واقع از همون اول در وضعیت شبیه به Tier 1 کار میکند.
مزیت:
Startup همیشه سریع است.
هیچ overheadی برای JIT یا re-optimization وجود ندارد.
ولی بهینهسازی به اندازهی JITهای adaptive (مثل .NET یا V8) عمیق نیست
| ویژگی | NET 10. | Node.js (V8) | Go |
|---|---|---|---|
| Tier 0 | JIT سریع، بدون boxing غیرضروری | Interpreter (Ignition) | ندارد |
| Tier 1 | JIT optimized (بعد از پروفایل) | TurboFan Optimized Code | همیشه از قبل بهینه |
| Startup Speed | خیلی سریع | سریع (با interpreter) | خیلی سریع |
| Long-term Speed | عالی (بعد از JIT optimizations) | عالی (تا وقتی deopt نشود) | پایدار ولی سادهتر |
| ریسک rollback | ندارد | دارد (deoptimization) | ندارد |
بهینهسازی حلقهها شامل تکنیکهایی مثل strength reduction (جایگزینی عملیات سنگین با سادهتر) و شمارش رو به پایین (downward counting) است که اجرای حلقهها را سریعتر میکند.

حلقهها (loops) معمولاً بیشترین زمان اجرای برنامه را مصرف میکنند.
برای همین کامپایلرها چند تکنیک مهم بهینهسازی حلقه دارند:
Strength Reduction
جایگزینی یک عملیات پرهزینه با عملیات سادهتر.
مثال:
for (int i = 0; i < n; i++)
{
x = i * 4;
}
در Strength Reduction → ضرب (multiplication) با جمع (addition) جایگزین میشود:
x = 0;
for (int i = 0; i < n; i++) {
x += 4;
}
Loop Unrolling
for (int i = 0; i < n; i++)
{
sum += arr[i];
}
بعد از Unrolling (مثلاً 4 بار):
for (int i = 0; i < n; i += 4)
{
sum += arr[i] + arr[i+1] + arr[i+2] + arr[i+3];
}
نتیجه:
کاهش هزینهی محاسباتی
بهبود سرعت در حلقههای سنگین
JIT در .NET 10 حتی قویتر از نسخههای قبل شده و بهینهسازیهای زیر را انجام میدهد:
Strength Reduction → ضرب و تقسیمهای ثابت به جمع و شیفت تبدیل میشوند.
Downward counting loops → حلقههایی که شمارش رو به پایین دارند کاراتر میشوند.
Bounds check elimination → وقتی مطمئن باشد که ایندکس از محدوده خارج نمیشود، چکهای اضافی حذف میشوند.
Loop unrolling پیشرفتهتر در حلقههای کوچک یا hot.
ترکیب با Vectorization برای پردازش موازی دادهها.
📌 نتیجه: کارایی در workloadهای علمی، پردازش تصویر، یادگیری ماشین و دیتابیس به شدت افزایش یافته است.
V8 هم بهینهسازیهای مشابه دارد:
Strength Reduction روی ضرب/تقسیم انجام میشود.
Loop-Invariant Code Motion → محاسبات ثابت به بیرون حلقه منتقل میشوند.
Bounds Check Elimination وقتی دادهها monomorphic (یک نوع مشخص) باشند.
Unrolling محدود بیشتر در hot paths انجام میشود.
📌 اما به خاطر dynamic typing در جاوااسکریپت، این بهینهسازیها همیشه قابل اعتماد نیستند.
اگر در یک iteration عدد صحیح بیاید و در دیگری رشته، ممکن است کل حلقه deoptimized شود.
Go یک زبان AOT compiled است، پس همهی بهینهسازیها در زمان build اتفاق میافتد.
Strength Reduction و Loop-Invariant Code Motion به خوبی پشتیبانی میشوند.
Loop Unrolling به صورت محدود استفاده میشود (معمولاً برای حلقههای خیلی کوچک).
چون نوع دادهها در Go استاتیک هستند → این بهینهسازیها پایدارتر از Node.js هستند.
📌 نقطه ضعف:
Go به اندازهی JITهای هوشمند مثل .NET یا V8 aggressive نیست.
تمرکز Go بیشتر روی سادگی و build سریع است تا heavy optimizations.
| ویژگی | NET 10. | Node.js (V8) | Go |
|---|---|---|---|
| Strength Reduction | کامل و پیشرفته | کامل (ولی ممکن است deopt شود) | کامل |
| Loop Unrolling | پیشرفتهتر و adaptive | محدود (hot paths) | محدود |
| Bounds Check Elimination | گسترده و هوشمند | بله، ولی حساس به نوع داده | بله (compile-time) |
| Downward counting support | بله | محدود | بله |
| Adaptive optimizations | بله (runtime JIT + vectorization) | بله (اما ریسک deopt) | ندارد |
| Performance در workload سنگین | 🔥 عالی | خوب (تا وقتی نوع داده تغییر نکند) | خوب و پایدار ولی نه در سطح .NET |
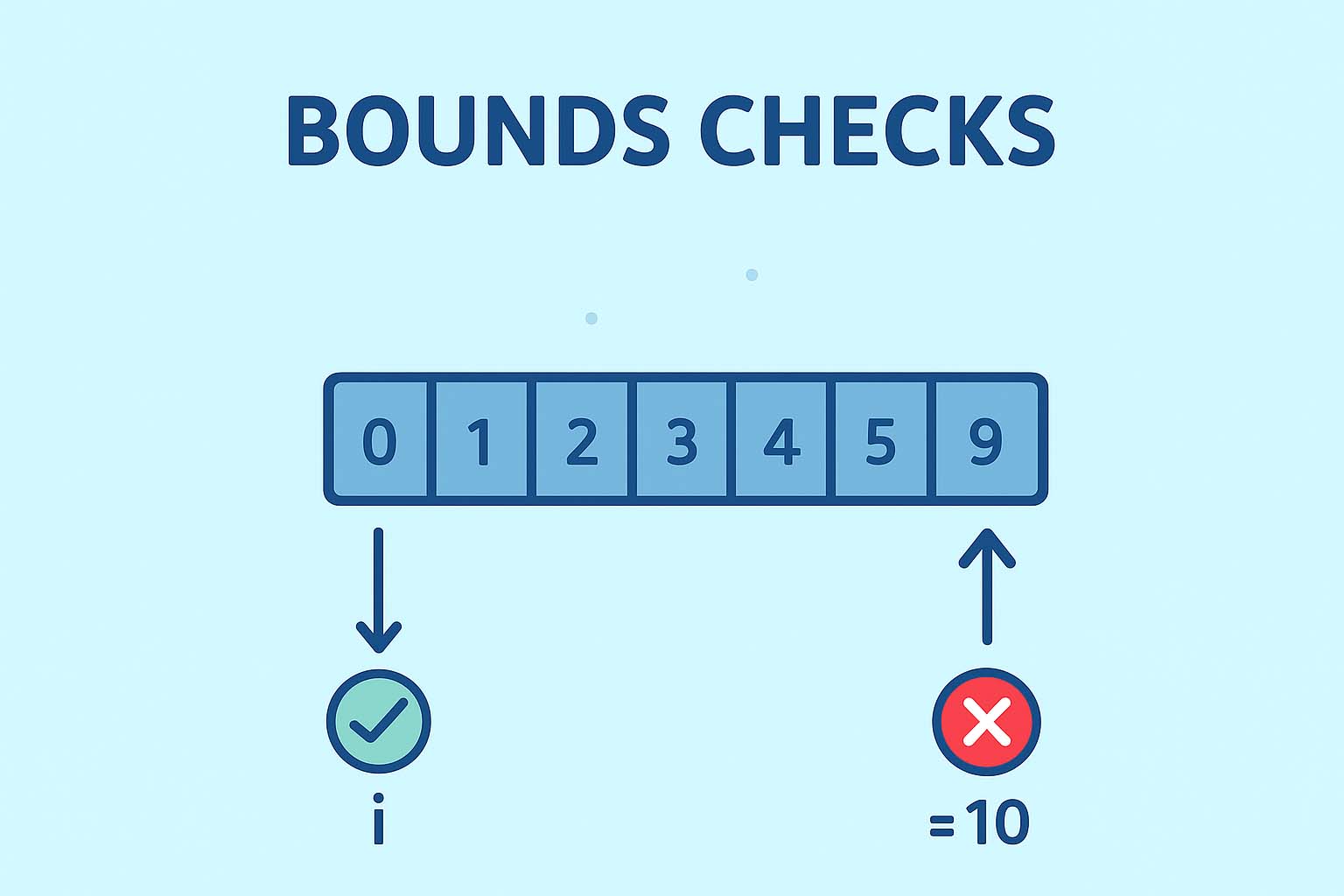
در زبانهای امن (مثل C#, Java, Go, JavaScript)، دسترسی به آرایهها یا لیستها همیشه با یک بررسی محدوده (Bounds Check) همراه است.
مثال در C#:
int[] arr = new int[10]; int x = arr[i]; // JIT بررسی میکند که 0 <= i < 10
مزیت: از خطاهای حافظه مثل Buffer Overflow جلوگیری میکند.
عیب: هر بار یک شرط اضافه اجرا میشود → افت کارایی در حلقههای بزرگ.
در . .NET 10. ، JIT بهبود بزرگی در این زمینه داده است:
for (int i = 0; i < arr.Length; i++)
sum += arr[i]; // چکها حذف میشوند چون i همیشه معتبر است
چکها را از داخل حلقه بیرون میکشد تا فقط یک بار بررسی شوند.
نتیجه: امنیت + سرعت همزمان → نزدیک به C++ در کارایی، ولی ایمنتر.
for (let i=0; i<arr.length; i++)).Int32Array سریعترند چون اندازهشان ثابت است.یعنی در حلقههای ساده، V8 خیلی سریع میشود، ولی در دادههای پویا، همیشه هزینهی اضافه دارد.
for i := 0; i < len(arr); i++ {
sum += arr[i] // check حذف میشود
}
Go مثل .NET خیلی پیشرفته در BCE نیست، ولی از Node.js پایدارتر است چون نوعها استاتیک هستند.
مقایسه Bounds Checks در سه پلتفرم
| ویژگی | NET 10. | Node.js (V8) | Go |
|---|---|---|---|
| Bounds Check Elimination | بسیار پیشرفته | بله، ولی محدود به الگوهای ساده و دادههای ثابت | بله، ولی سادهتر |
| Hoisting | بله (خارج کردن از حلقه) | بله (در برخی موارد) | بله |
| Static vs Dynamic Types | استاتیک → پایدار | داینامیک → risk deopt | استاتیک → پایدار |
| کارایی در حلقههای سنگین | نزدیک به C++ | خوب، مگر اینکه دادهها متغیر شوند | خوب، کمی ضعیفتر از .NET |
| امنیت حافظه | کامل | کامل | کامل |

مایکروسافت در NET 10. تمرکز زیادی روی ARM64 گذاشته چون:
بهبودها:
کد جنریشن بهینهتر در JIT
نتیجه:
ولی:
اما:
مقایسه Arm64 در سه پلتفرم
| ویژگی | NET 10. | Node.js (V8) | Go |
|---|---|---|---|
| JIT / AOT Optimizations | JIT و AOT بهینه برای ARM64 | JIT (TurboFan) با پشتیبانی خوب | AOT compiler بهینه |
| SIMD / Vectorization | بله (Arm64 SIMD) | بله (برای TypedArray و ریاضی) | محدود، هنوز سادهتر |
| Apple M1/M2 Performance | عالی (۲x–۳x نسبت به نسخههای قبلی) | خوب (بهینه برای مرورگر و Node) | خوب ولی بدون SIMD پیشرفته |
| Cloud ARM Servers | بهینه و سریع | پایدار، ولی تمرکز کمتر روی HPC | عالی (AWS Graviton محبوب برای Go) |
| Energy Efficiency | خیلی خوب (native optimizations) | خوب | خوب |
ARM SVE (Scalable Vector Extension) -7
پشتیبانی از SVE در معماری ARM امکان اجرای عملیات برداری (vectorized operations) به صورت کارآمدتر و در مقیاس بزرگتر را فراهم میکند.
این قابلیت مخصوصاً برای محاسبات علمی، هوش مصنوعی، پردازش تصویر و دادههای بزرگ بسیار مهم است.
نتیجه: محاسبات سنگین (مانند AI و پردازش داده) در .NET روی ARM خیلی سریعتر میشود، بدون نیاز به بازنویسی کد.
یعنی: Node.js روی ARM از SIMD پشتیبانی دارد، ولی هنوز SVE-aware نیست.
📌 یعنی: Go هم مثل Node.js هنوز SVE-ready نیست، ولی چون کدش استاتیک است، احتمالاً زودتر از Node میتواند بهره ببرد.
| ویژگی | .NET 9 | Node.js (V8) | Go |
|---|---|---|---|
| پشتیبانی SVE | بله (مقدماتی در JIT و AOT) | هنوز ندارد | هنوز ندارد |
| Vector<T> API | بهینهسازی شده با SVE | فقط SIMD قدیمی (NEON) | SIMD محدود |
| محاسبات علمی/AI | بسیار سریع | محدود | محدود |
| قابلیت اجرا روی CPUهای مختلف | بله (با SVE scaling) | خیر | خیر |
| تمرکز اصلی | HPC, AI, Big Data | وب و اپلیکیشنهای پویا | سیستمهای ساده و Cloud-native |
AVX10.1 Instructions -8
با اضافه شدن دستورالعملهای AVX10.1، کارایی محاسبات سنگین و عملیات پردازشی روی سختافزارهای سازگار افزایش یافته است.
مزایا:
نتیجه: در اپلیکیشنهای سنگین (مثل ML.NET, پردازش تصویر, بازیها) سرعت چشمگیری خواهید داشت.
یعنی Node.js روی CPUهای جدید، بهبود محدود میگیرد (نه به اندازه .NET).
یعنی در حال حاضر Go هم مثل Node.js فقط از AVX2/AVX-512 بهره میبرد.
| ویژگی | NET 10. | Node.js (V8) | Go |
|---|---|---|---|
| پشتیبانی AVX10.1 | بله (از طریق JIT و HWIntrinsics) | هنوز ندارد (فقط AVX2/AVX-512) | هنوز ندارد (فقط AVX2/AVX-512) |
| Vector API | بله (System.Numerics.Vector, HWIntrinsics) | SIMD محدود (TypedArray) | SIMD محدود (crypto و math) |
| کاربرد در ML/AI | عالی (ML.NET, Tensor libs) | محدود | محدود |
| Native AOT روی CPU جدید | مستقیم با AVX10.1 | ندارد | ندارد |
| پرفورمنس روی HPC | خیلی بالا | متوسط | متوسط |
AVX512 Support -9
پشتیبانی از AVX512 اجرای عملیات دادهمحور و محاسبات عددی در مقیاس بالا را بسیار سریعتر میکند، مخصوصاً در بارهای کاری علمی و محاسباتی.
مزیت: اجرای عملیات دادهمحور با حداکثر بهرهوری از CPU
نتیجه:
📌 نتیجه: Node.js برای محاسبات سنگین برداری روی CPUهای جدید محدودیت دارد.
نتیجه: Go از پردازش برداری استفاده میکند ولی نه در حد .NET
مقایسه AVX-512 در سه پلتفرم
| ویژگی | NET 10. | Node.js (V8) | Go |
|---|---|---|---|
| پشتیبانی AVX-512 | کامل (JIT + HWIntrinsics) | ندارد | محدود (crypto / برخی intrinsics) |
| Vector API | System.Numerics.Vector<T> | SIMD محدود | محدود |
| کاربرد در HPC / ML | عالی | محدود | محدود |
| Native AOT | مستقیم با AVX-512 | ندارد | ندارد |
| Performance | بسیار بالا | متوسط | متوسط |
Vectorization یعنی استفاده از دستورالعملهای پردازنده (SIMD: Single Instruction, Multiple Data) برای پردازش همزمان چند داده در یک دستور.
به جای اینکه عملیات روی یک عنصر انجام شود، چندین عنصر در یک رجیستر پردازنده بهصورت موازی پردازش میشوند.
📌 مثال ساده:
بدون Vectorization
for (int i = 0; i < n; i++)
{
arr[i] = arr[i] * 2;
}
با Vectorization (SIMD):
// هر بار 4 یا 8 عنصر با هم پردازش میشوند Vector v = new Vector(arr, i); v = v * 2; v.CopyTo(arr, i);
در .NET 10، JIT بهبود بزرگی در Auto-Vectorization دارد:
تبدیل خودکار حلقههای ساده به SIMD instructions.
پشتیبانی از AVX-512 و AVX10.1 روی CPUهای جدید اینتل/AMD.
استفاده از ARM SVE (Scalable Vector Extension) در پردازندههای ARM.
بهینهسازیهای ترکیبی → vectorization + loop unrolling.
📌 نتیجه:
عملکرد بسیار بالا در پردازشهای دادهمحور مثل:
پردازش تصویر
الگوریتمهای علمی
یادگیری ماشین
V8 به طور مستقیم vectorization انجام نمیدهد.
اما:
کامپایلر TurboFan بعضی حلقههای عددی را بهینه میکند.
برای SIMD واقعی نیاز به WebAssembly SIMD یا کتابخانههای مخصوص (مثل TensorFlow.js) است.
📌 نتیجه:
در پردازشهای عادی جاوااسکریپت → vectorization به صورت خودکار ضعیف است.
در WebAssembly → میتواند به سطح C/C++ نزدیک شود.
Go یک زبان AOT است و خودش به طور پیشفرض auto-vectorization انجام نمیدهد.
اما:
با فلگهای کامپایلر GCC/LLVM میتوان بعضی از حلقهها را vectorize کرد.
پکیجهایی مثل intrinsics یا assembly-level SIMD برای کارهای خاص استفاده میشوند.
📌 نتیجه:
در Go بهینهسازی پیشفرض محدود است.
توسعهدهنده باید به صورت دستی (با پکیج یا asm) vectorization را فعال کند.
مقایسه vectorization در سه پلتفرم
| ویژگی | .NET 10 | Node.js (V8) | Go |
|---|---|---|---|
| Primitive types | استاتیک + SIMD پیشرفته | Dynamic → hidden classes | استاتیک |
| Boxing/Unboxing overhead | حذف شده (با generic math) | زیاد (به خاطر dynamic typing) | ندارد |
| Enumeration روی Array/List | 🔥 بسیار سریع (inline + حذف bound checks) | سریع، اما حساس به نوع داده | سریع و پایدار |
| Enumeration روی Object/Map | سریعتر از قبل | کندتر (for..in ضعیف) | بهینه و compile-time |
| Predictability | متوسط–بالا (adaptive JIT) | کم (dynamic typing) | بالا (compile-time) |
| Performance در workload سنگین | 🔥 عالی | متوسط | خوب و پایدار |
Branching Improvements
با بهبود در پیشبینی شاخهها (branch prediction)، جریمه ناشی از misprediction کاهش پیدا کرده و کارایی کلی CPU بهتر شده است.
if (x > 0) { doSomething(); } else { doSomethingElse(); }
📌 مشکل: در حلقهها و برنامههای محاسباتی سنگین، branch misprediction میتواند کارایی را تا ۳۰–۵۰٪ کاهش دهد
📌 نتیجه:
📌 نتیجه: برای وب و کدهای سبک خوب، ولی در کدهای محاسباتی سنگین کمتر پایدار
📌 نتیجه: Go در branch prediction پایدار است ولی نمیتواند مسیرهای اجرای dynamic را همانند .NET بهینه کند
| ویژگی | .NET 9 | Node.js (V8) | Go |
|---|---|---|---|
| Branch Prediction | JIT adaptive با hot/cold paths | Speculative + risk deoptimization | Compiler heuristics |
| Hot Path Optimization | بله | بله ولی پویا و ممکن است rollback شود | محدود |
| Performance در حلقههای سنگین | بسیار خوب | متوسط | خوب |
| Handling Dynamic Types | بله | بله ولی با risk | نه |
Write Barriers Optimization
بهینهسازی write barrierها در GC سربار مدیریت حافظه را کاهش داده و کارایی جمعآوری زباله (Garbage Collection) را افزایش میدهد.
📌 مشکل: هر write barrier باعث overhead و کندی برنامه میشود
📌 نتیجه:
📌 نتیجه: برای workloadهای وب مناسب است، اما در برنامههای memory-heavy عملکرد GC کمتر بهینه است
📌 نتیجه: برنامهها پایدار و امن هستند ولی throughput GC به اندازه .NET بالا نیست
| ویژگی | .NET 9 | Node.js (V8) | Go |
|---|---|---|---|
| نوع GC | Generational + Concurrent GC | Incremental + Generational | Concurrent, Non-generational |
| Write Barrier Optimization | بسیار بهینه (حذف write غیرضروری با JIT) | پیادهسازی سادهتر، adaptive | ساده و پایدار، کمتر بهینهشده |
| Overhead | کم (Reduced Barrier Overhead) | متوسط (به دلیل dynamic typing) | کم، ولی throughput پایینتر از .NET |
| Throughput | خیلی بالا 🚀 | مناسب برای workloadهای وب | پایدار، اما کمتر از .NET |
| مناسب برای | برنامههای server-side, HPC, پردازش سنگین | وباپلیکیشنها و APIها | سیستمهای پایدار و ایمن (Cloud, Microservices) |
Object Stack Allocation
این ویژگی باعث میشود اشیای کوتاهعمر به جای heap روی stack تخصیص پیدا کنند. نتیجه: کاهش فشار روی GC و افزایش سرعت.
📌 محدودیت: فقط برای اشیایی که scope محدودی دارند و طول عمرشان کوتاه است
Span<T> یا stackalloc دستی.| ویژگی | .NET 10 | Node.js (V8) | Go |
|---|---|---|---|
| Escape Analysis | بله، پیشرفته (runtime JIT) | بله، محدود به دلیل dynamic typing | بله، compile-time |
| Stack Allocation خودکار | بله، برای اشیاء کوچک و کوتاهعمر | محدود | بله |
| فشار روی GC | کم (بهبود چشمگیر) | زیاد (اکثر اشیاء در Heap) | کم |
| Predictability | متوسط (adaptive JIT) | کم (dynamic typing) | بالا (compile-time) |
| Performance در workload سنگین | 🔥 عالی | متوسط | خوب و پایدار |
درباره نویسنده

سعید شایان مهر
کارشناس مهندسی نرم افزار، مدیر و موسس وب سایت شایاسافت، طراح و توسعه دهنده ارشد نرم افزار،وبسایت با زبان برنامه نویسی سی شارپ و تکنولوژی دات نت، طراح و توسعه دهنده بازی های ویدئویی با موتور بازی سازی یونیتی، 2 سابقه تدریس رشته کامپیوتر و برنامه نویسی در هنرستان، 10 سال سابقه فعالیت بطور حرفه ای در حوزه طراحی وب سایت،وب اپلکیشن، ساخت بازی های ویدئویی، طراحی نرم افزار در محیط ویندوز و اندروید ، 8 سال سابقه همکاری با کافه بازار بعنوان توسعه دهنده نرم افزار و بازی، توسعه دهنده حال حاضر دات نت در گروه نرم افزاری محک
لینک کوتاه
www.shaya-soft.ir/p/46
موسسه شایاسافت از سال 92 با ساخت نرم افزار های ویندوزی شروع بکار کرد.و با گذر زمان در زمینه های طراحی بازی و نرم افزار های اندرویدی و همچنین چند سکویی و طراحی وبسایت فعالیت میکند.و اکنون پس از سال ها پروژه های زیادی در زمینه مختلف ارائه نموده است.همچنین این مجموعه در زمینه های آموزش های برنامه نویسی و مهندسی نرم افزار فعالیت میکند